NBA下注(中国)官网 Anthropic万字长文: AI正在成为我方的“造物主”


若是你以为AI还只是帮你改改邮件、写写周报的小助手,那可能有点低估它了。Anthropic最近把我方家底翻了一遍,发现一个有点轰动的事实: AI正在成为我方的“造物主”。
圣洁说等于,从前AI怎样进化,每一步都得东说念主盯着、东说念主动手。但目前,Anthropic越来越多地把AI开拓的责任,径直交给AI我方干。驱散是:工程师每季度合并的代码量,是当年几年的 8倍 ;超越80%的新代码是Claude写的;有些耗时几天的活儿,它两小时就干收场。更历害的是,AI不光耀眼活,还能作念判断。比如给一个绽开的谋划问题,它我方能遐想实验、跑驱散、找谜底。在一个AI安全测试里,两个东说念主类谋划员花了一周料理了23%的问题,Claude用800小时和一万八千好意思元的算力,料理了 97% 。按照这个速率,AI能独处完成的任务时长,毛糙每四个月翻一倍。旧年3月它耀眼4分钟的活儿,本年还是耀眼12小时的了。按照这个趋势, 2027年附近,AI可能就耀眼东说念主类需要好几周才能完成的事 。虽然,Anthropic也说了,这还不是“AI澈底我方造我方”的那一天——但阿谁叫“递归式自我完善”的东西,可能比大大都东说念主想的来得快。好的一面是,科学、医疗、出产力可能会被推着跑起来。不好的一面是,若是AI真的能我方造我方,东说念主类怎样保证还能“管得住”它,就成了一个天大的问题。这篇著述有点长,但值得看完!
以下为编译。
在 AI 发展史上的大大都时刻里,东说念主类主导了它开拓周期中的每一个环节。但在 Anthropic,咱们正把越来越多的 AI 开拓责任委用给 AI 系统我方完成,而这正在显赫加速咱们的责任速率。
若是把这一趋势连续推远,并赐与满盈多的算力,它最终会指向一种 AI 系统:它能够完全自主地遐想并开拓我方的后继版块。这被称为 递归式自我立异 (recursive self-improvement)。咱们还莫得走到那一步,而且递归式自我立异也并非势必发生。但它到来的时刻,可能会比大大都机构准备得更早。
借助公开基准测试,以及此前从未对外皮露的 Anthropic 里面数据,Anthropic Institute 正在展示一个事实:AI 还是驱动加速 AI 系统自己的开拓。举一个例子:今天,Anthropic 工程师平均每个季度托福的代码量,还是是 2021—2025 年时间的 8 倍。
本文商议的工夫趋势标明,将来几年 AI 系统的才调还将大幅种植。这些趋势真义紧要。能够“构建我方”的 AI,将会是工夫史上的一个紧要节点——它可能像 《Machines of Loving Grace》 所描绘的那样,在科学、医疗等领域为寰宇带来巨大的善意与跳跃。但完全真义上的递归式自我立异,也可能增多东说念主类失去对 AI 系统适度的风险。若是系统真的具备完全构建其后继版块的才调,那么咱们怎样保险其安全、怎样监控它、怎样塑造它的活动,都会变得迂回得多。
1 来自外部寰宇的字据
AI 模子种植的速率正在加速。它们能够可靠独处完成的任务时长,还是从更早期毛糙每七个月翻一倍的趋势,加速为如今毛糙每四个月翻一倍。2024 年 3 月,Claude Opus 3 还能完成毛糙极端于东说念主类 4 分钟责任量的软件任务。一年之后,Claude Sonnet 3.7 还是能处理极端于东说念主类约 1 个半小时的任务。再过一年,Claude Opus 4.6 还是能完成 12 小时级别的任务。[^1] 若是这一趋势延续下去,那么本年之内,老到东说念主员需要花上数天才能完成的任务,就可能进入 AI 的才调范围;到 2027 年,AI 系统无意将能胜任那些东说念主类需要数周才能完成的任务。
相同的模式也出目前编码与谋划基准测试上。基准测试估量的是模子在某一特定领域中的阐明,而当模子收货接近 100% 时,咱们就说该基准被“饱和”了。[^2] SWE-bench 是现实寰宇软件工程的尺度测试之一:它会给模子一个真实的开源代码库和一份真实 bug 讲演,要求模子写出能确立问题、并通过状貌自身测试的代码变更。只是两年时刻,模子就在这个基准上从个位数低分一齐走到接近饱和。
CORE-Bench 测试的是模子能否复现已有谋划驱散,这亦然其将来开展原创谋划的前提。测试方式是向 AI 模子提供一篇已发表论文背后的代码与数据,并要求它再交运行全部经由,阐明我方能够复现实验论断。AI 系统在 2024 年时,复现告捷率毛糙惟有 20%;而只是 15 个月之后,这一基准也已趋于饱和。考究万古任务才调评测的 METR 还发现,Claude Mythos Preview 还是能够责任“至少”16 小时,而且还是“涉及 [METR] 在不引入新任务前提下可测量才调的上限”。
公开基准不错告诉咱们好多对于系统才调自己的信息,但它们无法径直揭示 AI 系统究竟在多大程度上加速了 AI 自身的开拓。要回复这个问题,咱们需要来自 Anthropic 这类 AI 公司里面的一手字据。
2 Anthropic 里面的字据
构建一个前沿模子,大致可分为两类责任。其一是 工程 :编写代码、搭建基础设施、监督模子老师。其二是 谋划 :决定要作念哪些实验、说明实验复返的驱散,并判断接下来该尝试哪些看法。
不管在工程照旧谋划上,呈现出的图景都极端一致。在工程侧,Claude 还是能够接收一个界说并不充分的问题,然后自行摸索料理旅途;东说念主类提供的是目的,但不再需要提供门径。在谋划侧,Claude 还是不错在履行一个界说通晓的实验时,达到以致超越老到东说念主类谋划者的水平。不外,在工程和谋划中,Claude 在“采用目的”时所需的判断力上,依然存在昭彰才调差距。这恰是今天的 AI 与将来那种不错自主遐想我方后继者的系统之间的隔离。
在 Anthropic,职工平方会跟着素质增长而接到越来越绽开、也越来越迂回的任务。初期,他们履行别东说念主还是界说好的任务,比如:“导出按钮坏了,请修一下。” 跟着素质增多,他们会拿到一个目的,然后我方遐想杀青旅途,比如:“调查一下为什么相聚在高负载下会变慢。” 而到了最资深的层级,他们决定的还是是“什么问题值得作念”,例如:“团队下个季度应该作念什么?” 咱们不错借助 Anthropic 里面数据,望望 Claude 在应付这些不同类型任务方面还是走到了哪一步。
Claude 正在编写 Anthropic 极端大比例的代码。 甩掉 2026 年 5 月,Anthropic 代码库中合并进主分支的代码里,超越 80% 出自 Claude。[^3] 在 2025 年 2 月 Claude Code 谋划预览版发布之前,这个数字还只是个位数低位。这种变化也体目前了工程师的东说念主均产出上。Anthropic 创立最初四年(2021—2024),每位工程师每天合并的代码行数基本保持自若;到了 2025 年,当 Claude 驱动不再只是“建议代码”,而是径直“运行代码”时,这条弧线驱动进取抬升;到了 2026 年,模子能够在更万古刻跨度上自主责任后,斜率再次昭彰变陡。底下这张图展示了这两个拐点。到 2026 年第二季度,典型工程师每天合并的代码量,还是是 2024 年时的 8 倍。[^4] 原因很圣洁:好多代码还是由 Claude 写出,而工程师的变装转向了提示与审阅,而不是亲手逐行敲写。
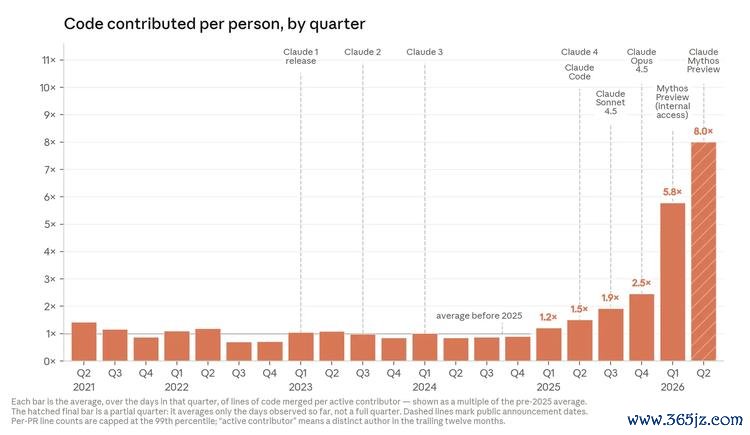
虽然,需要难得的事:代码行数并不是齐全目的,因为它估量的是数目而不是质地。是以,2026 年第二季度“每位工程师每天 8 倍代码行数”,险些信赖高估了真实出产率种植的幅度。但不管怎样,它说明了一件事:速率正在加速。在 Anthropic,咱们并不会按照“你写了若干行代码”来奖励职工;团队成员之是以产出更多代码,只是因为他们正在用 AI 系统写出更多代码。
代码行数的增长,也与职工对出产率显赫种植的主不雅感受相吻合。2026 年 3 月,在 Anthropic 谋划团队 130 名职工参与的一项调查中,受访者中位数臆想:在“不管怎样本来也会作念的那些状貌”上,使用 Mythos Preview 后,他们的产出毛糙是“完全莫得 AI 可用”情况下的 4 倍。[^5] 咱们瞻望,3 月时真实的种植幅度可能比这个数字略低。[^6] 尽管如斯,咱们依然认为合座论断的确,也与咱们的其他不雅察一致:Anthropic 中极端一部分工夫职工,正在以莫得 AI 匡助时数倍的速率完成我方的中枢责任。
咱们还看到一些字据标明,Anthropic 职工正愚弄 Claude 去完成那些若是莫得 AI,本来根柢不会去作念的责任,比如搭建探索性器用、或者计帐那些历久被甩掉的问题。例如来说,2026 年 4 月,Claude 一次性托福了 800 多个确立,把某一类 API 失误减少到了原本的千分之一。考究监督 Claude 的工程师臆想,若是让东说念主类来作念,这项责任需要整整 4 年;修别东说念主的 bug 本来等于一件渐渐、繁琐、极其铺张元气心灵的事,而东说念主类也很难同期在脑中看护如斯宏大且生分的荆棘文。
“毛糙一年前,我驱动相称激进地鼓吹‘Claudifying’。那是一段相称轻易的旅程,而到目前,概况还是有 5 个月,我再也没亲手写过任何代码了。”——Anthropic职工
Claude 写出来的代码是“好的”,而且还在持续变好。 “好代码”包含两层含义:第一,它能正常责任;第二,它的写法要让另一位工程师能够交融、并连续在其上迭代。对第一条尺度而言,字据还是很了了。当年一年里,Anthropic 职工在职务进行过程中对 Claude 进行矫正、重定向,或径直接受的频率一直在稳步下跌,哪怕是在最复杂、最绽开的问题上亦然如斯。所谓“绽开问题”,是指那些莫得明确规格说明、工程师我方也省略情正确谜底长什么样的问题。下图展示了 Claude 在不同难度任务上的告捷率变化。Claude 还是能写出真实可运行的代码。
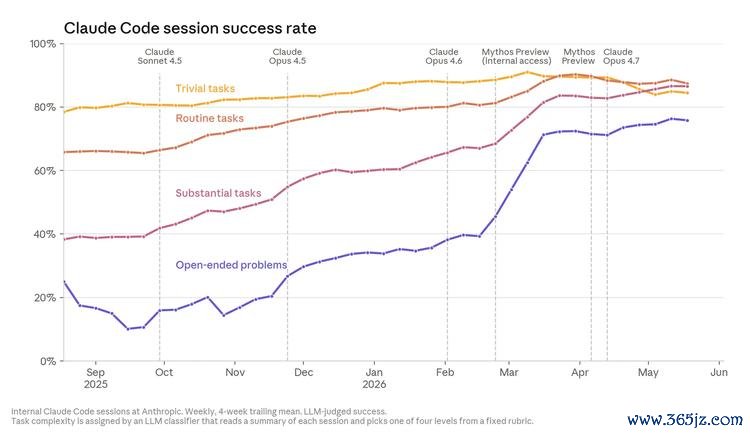
怎样交融这张图: 会话是否告捷,由一个 Claude 裁判来判断;若是 Claude Code 代理昭彰完成了用户任务,而且过程中不需要东说念主为矫正,则该会话被视为告捷。责任负载的变化可能导致告捷率出现短期波动。
在最绽开的那类任务上,Claude 的告捷率到 2026 年 5 月还是达到 76%,在 6 个月内提高了 50 个百分点。举个这类任务的例子:一次惯例升级导致泛滥成灾的老师功课崩溃。一位工程师险些只给了 Claude 少量文本信息和集群走访权限,就把实步地故交给它处理。Claude 一边查验运行中的功课,一边逐项测试环境建立,最终锁定了一个触发崩溃的隐秘调试绚烂位,告捷自若复现问题,并阐明了解法。毛糙两小时内,Claude 完成了平方需要两到三天才能作念完的责任。
第二条尺度,是代码是否写得满盈通晓,让另一位工程师能看懂并在其上连续开拓。在这少量上,东说念主类与 AI 之间的差距依然存在,但正在速即松开。Anthropic 里濒临此并非完全一致,但许多东说念主认为:在 2025 年末,Claude 写的代码质地仍昭彰逊于 Anthropic 工程师我方写的代码;而到今天,两者还是大致持平。咱们瞻望,在一年之内,Claude 写出的代码会更好。
这也改变了 Anthropic 审查代码的方式。如今,提交到代码库中的变更会先由一个自动化的 Claude 审阅器读取,它会在代码合并之前查验 bug、安全罅隙以过头他劣势。愚弄这一器用,咱们作念了一次回溯分析,发现:若是当年对代码库中的每一次篡改都进行自动化 Claude 审查,那么 claude.ai 过旧事故背后毛糙三分之一的 bug,本来都不错在进入出产环境之前就被阻碍下来。写下那些代码的工程师,自己还是是寰宇上最擅长构建这类系统的东说念主之一。如今,Claude 还是能收拢他们遗漏的失误。
“在 2025 年末,Claude 写的代码质地还比 Anthropic 东说念主类工程师写的差一些;今天,它大致还是达到同等水平;而咱们瞻望,在一年内它会严格真义上超越东说念主类。” ——Anthropic职工
Claude 还是很擅长围绕别东说念主设定的目的来跑实验。 每次 Anthropic 发布新模子时,咱们都会进行吞并个测试:给 Claude 一段用于老师袖珍 AI 模子的代码,要求它在仍通过相通正确性查验的前提下,把这段代码跑得尽可能快。目的和评估尺度事前就被固定好了,是以 Claude 的任务等于通过改写代码、运行代码、计时,再叠加这一过程来寻找加速门径。这极端于一个松开版的实验谋划闭环。2025 年 5 月,Claude Opus 4 比拟肇始代码平均杀青了约 3 倍加速;到 2026 年 4 月,Claude Mythos Preview 还是达到约 52 倍。看成参照,一个老到的东说念主类谋划员平方需要 4 到 8 小时,才能作念到 4 倍。[^7] 在谋划经由的这一环——也等于在界说通晓的实验里作念门径优化——Claude 在不到一年的时刻里,就从“相称有匡助”跨越到了“超越东说念主类”。
“今天的合座形态大致是:东说念主类提议看法,而模子能以比当年快一个数目级的速率,把这些看法杀青、测试并评估出来。” ——Anthropic职工
Claude 正越来越擅长提议我方的实验。 2026 年 4 月,Anthropic 发布了第一个由 Claude 端到端完成绽开式谋划状貌的演示。谋划东说念主员给 Claude 驱动的代理们一个 AI 安全方进取的绽开问题——大致来说,是“较弱模子是否不错可靠监督较强模子?”——然后让它们我方去料理。这个过程包括提议假定、进行实验、与并行代理分享发现,并连接迭代。这个任务有通晓的阐明“地板”和“天花板”:地板是弱监督模子单独责任时能达到的水平;天花板则是强模子在使用正确谜底老师后达到的水平。两位东说念主类谋划者花了毛糙一周时刻,还原了其中约 23% 的差距;而这些代理累计责任 800 小时、铺张约 1.8 万好意思元算力后,还原了 97%。虽然,这项责任也有一些规则:驱散并莫得顺利移动到出产限制的模子上,而且问题的采用和评分法律说明仍然由东说念主类设定。但在这些界限条目之内,代理们是我方遐想了每一个实验。东说念主类真实上演的独一关键变装,等于设定谋划目的。
“Claude 在 1 到 2 天里,险些没怎样需要我襄理,就把这一切作念收场。我想,若是一位[低级共事]在相同时刻里拿着这样的驱散追想找我,我会感到有点惊喜。将来还是来了。” ——Anthropic职工
Claude 正越来越擅长把谋划会话引向真实的谋划发现。 咱们分析了 Anthropic 谋划东说念主员在 2026 年 1 月到 3 月之间与 Claude 一齐责任的真实 Claude Code 会话,这些会话处理的都是绽开式调查问题,比如“为什么一次老师运行老是崩掉”,或者“为什么某个模子在基准测试上得分这样低”。在每个案例里,咱们都找到了谋划员半途“走弯路”的时刻:他们沿着一个失误方上前进,导致总计这个词会话偏离正轨,之后才再行拉追想。接着,咱们只把“会话偏离之前”的责任内容展示给多个 Claude 模子,并问它们下一步会怎样作念。然后,再由另一个能够看到总计这个词会话最终驱散的 Claude,来判断究竟是 AI 照旧东说念主类提议了更好的下一步。[^8]
由于咱们零散挑选了这些“东说念主类采用本来就有立异空间”的时刻(n=129),是以这并不是模子与东说念主类判断力的一次完全公正对照。这些时刻真实提供的是一组现实而困难的场景:正确的下一步并不赫然,而东说念主类那时的采用,恰好不错看成一个有用的标尺,来比较模子才调随时刻的变化。按照这一目的,咱们在 2025 年 11 月阐明最佳的模子(Opus 4.5),有 51% 的概率比东说念主类那时的采用更优;到 2026 年 4 月(Mythos Preview),这一比例高潮到 64%。谋划责任的日常,骨子上等于由一连串“下一步该作念什么”的决策组成,因此,这不错看成估量模子将来能否自主鼓吹调查谋划的一个有关目的。咱们把这一驱散视为一个早期信号:AI 系统正在越来越擅长作念出那些 AI 谋划自己所依赖的判断。
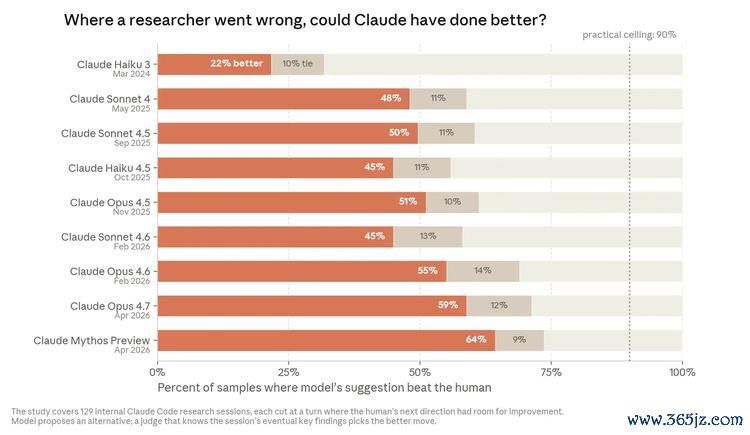
怎样交融这张图: 图中的“实践天花板线”代表一种“盼愿谜底”——它由一个能看到总计这个词会话全过程(包括其后怎样收尾)的模子写出。
“甩掉目前,东说念主类的比较上风仍然在于:看见更大的图景,况且能够跳出咫尺任务的界限去想考。” ——Anthropic职工

3
Anthropic 的责任将来可能会是什么样?
这些字据标明,NBA下注(中国)官网入口在 AI 开拓经由中的每一步,东说念主类所上演的变装都在收缩。一朝东说念主类与 AI 所写代码的质地达到同等水平,东说念主类就会澈底罢手躬行写代码,而只保留审阅这一职责。但若是东说念主类审代码的速率赶不上 Claude 生成代码的速率,那么代码审阅自己就会成为 AI 开拓的新瓶颈。相同,一朝 Claude 还是能独处跑实验,问题就会转向:“这些实验里,哪些值得跑?” 说得更径直一些:如今,“履行”——也等于写代码、跑实验、产出驱散——险些还是不再铺张东说念主类时刻,尽管它仍然铺张算力。
至少在目前,东说念主类的比较上风仍在于谋划品尝与判断力:包括哪些问题迂回、哪些驱散的确,以及什么时候该认定一条旅途还是走进死巷子。
“责任(以及生存)也曾建立在一种由东说念主与东说念主之间小匡助组成的‘礼物经济’上。‘你能帮我把这个剧本跑起来吗?’……每一次恳求都会形成少量点情面债,也会增多少量点彼此之间的感知。[Claude] 更快,而且不会制造任何情面债,但每一次这样的替代,也意味着一次东说念主类配合契机的流失。”“在一切都运转顺利的日子里,我会忍不住以为我作念什么都不迂回,一切都自动化了,而且比我更快、更好。但也有些日子,一切一霎都坏掉了,我又根柢不知说念为什么,于是我理解到,我方还是完全不知说念这些天究竟在作念什么了。” ——Anthropic职工
4 若是咱们错了呢?
对上头这些字据,一个很当然的反驳是:真实最迂回的责任,仍然掌合手在东说念主类手里——也等于决定“该作念什么问题”。若是莫得这种判断力,Claude 充其量只是一个才调很强的助手,而不是一个能够我方推动 AI 跳跃的系统。
今天的老师门径和模子架构,究竟能否解锁这种才调,照实还很不解确。但 AI 的跳跃很少来自那种“灵光一现”的顿悟时刻。连年 AI 历史中照实出现过一些这样的时刻,比如 Transformer 架构,或者夹杂大众(mixture-of-experts)模子;但真实改变范式的看法,往往几年才出现一次。在这中间,大部分跳跃其实都很“朴素”:把某个东西连续放大,望望那边出问题,修掉,再试一次。而这恰恰恰是 Claude 目前最擅长的责任流。爱迪生说,天才是 1% 的灵感加上 99% 的汗水。而咱们看到的是,“汗水”这一部分正在越来越自动化。越来越昭彰的少量是:推动前沿上前走的许多责任,自己等于可自动化的;大限制谋划进展,在很大程度上取决于器用和资源——它们决定了你能多快跑实验、一次能跑若干实验,以及你能多快拿到驱散。
即便咱们假定 Claude 永恒也得不到真恰恰的谋划品尝,对现存字据作念一个保守解读,也仍然意味着一种“复利式加速”。若是东说念主类把大部分时刻都花在阿谁位数比例的“目的设定”责任上,而剩余部分都交给 Claude 来作念,那么每位工程师或谋划者推行上都在同期独霸比当年多得多的责任量。咱们看到的字据标明,Anthropic 的职工不仅移动得更快,也覆盖了更广的责任面。在推行层面,这意味着:自从有用的 AI 器用出现之后,AI 还是让 Anthropic 的鼓吹速率比当年快得多。
而一种没那么保守的解读则是:尽管目前字据还很初步,但 Claude 在谋划判断力上的种植,也许说明这项才调自己也在跳跃。“谋划品尝”也许只是另一种典型的 AI 才调:系统会先在一段时刻内阐明得很差,然后一霎驱动变得擅长。近似的模式,咱们还是在其他更偏定性的才调上见过,比如 AI 系统驱动能够说明一个见笑为什么可笑、展现“心智表面”,或者解开说话谜题。
5 可能的将来
接下来会发生什么,取决于两件事:第一,这条趋势会不会连续;第二,若是连续,咱们会采用作念什么。咱们至少不错想象三种将来情状:
1. 趋势停滞,但今天的 AI 才调平庸扩散
这篇著述里出现了许多指数型轨迹。但这些轨迹也可能最终只是 S 弧线。咱们可能正接近弧线的弯折点:限制禀报驱动递减,增长线条先变直,再趋于缓慢。一个“及格谋划员”和“伟大谋划员”之间的隔离,所依赖的那种判断力,也许并弗成通过连续扩大老师输入(如算力和数据)来赢得。若是真实这样,那么要越过这一瓶颈,就需要一个新看法,比如一种能够取代刻下总计前沿模子所依赖的 Transformer 的新架构门路。
另外,规则 AI 进展的关键不休,也可能不在模子自己,而在供应链:前沿才调的鼓吹与扩散,也许需要比刻下寰宇可提供的更多动力和算力。制芯速率、电网扩容、互连带宽,也许才是真实的不休,而不是智能自己。咱们也弗成排斥某种外生冲击对 AI 生态变成一霎延缓的可能,比如算力或电力供应陡然收缩——不管哪一种,都会让跳跃变慢,也让前沿实验室连续干预的资本高潮。或者,也可能存在其他咱们尚未料想到的梗阻。
即使把模子才调冻结在今天的水平,咱们仍然瞻望寰宇会发生紧要变化。Project Glasswing 等于一个早期信号:在最初几周里,Mythos Preview 在全球最迂回的一些系统中发现了超越一万个高危和严重级别的软件罅隙,多到相聚防卫的瓶颈还是从“发现罅隙”转向“来不足修补罅隙”。而且,咱们仍处在今天这些模子向更平庸经济体系扩散的早期阶段——将来,一个 100 东说念主的公司,越来越可能作念出当年 1000 东说念主公司才能完成的责任,因为每一位职工死后都将站着一个代理金字塔。
之是以把这个情状列出来,是为了完整性;但咱们并不认为它最有可能发生。到目前为止,咱们能测量到的总计才调——包括那些看起来更“软”、更难量化的才调,比如代码质地和绽开任务告捷率——都撤职着相同的高潮弧线。咱们还莫得看到这条弧线驱动弯折。在咱们商议的三种将来里,这一种会给政府和社会最多的相宜时刻。比拟之下,咱们更记念后头两种,因为它们会来得更快,留给准备的空间也小得多。
2. AI 实验室连续赢得复利式着力种植
在这个情状里,AI 开拓将杀青极端程度的自动化,但谋划目的仍由东说念主类设定,驱散也仍由东说念主类裁定。使用 AI 系统的组织会跟着时刻推移变得越来越高效,因此咱们不错预期,每一个组织成员的出产力都会被成倍放大。一个 100 东说念主的公司,可能作念出 1 万东说念主以致 10 万东说念主组织才能完成的责任。这将澈底改造学问责任和政府服务,但它相同可能被用于无益目的:从针对总计这个词东说念主群的威权监控,到为每个个体量身定制、且以任何东说念主工团队都无法匹敌的限制运行的影响力操控。届时,在 Anthropic 这样的公司里,东说念主类的变装也会改变。东说念主们将与 AI 系统配合,放大谋划才调、生成新洞见,并共同建立那些用来考证 AI 输出是否的确的系统。
咱们在这里展示的字据标明,咱们很可能正在走向这个情状。但一个经由中某一环节的提速,往往只是把瓶颈推到了别处:合座速率终究受制于那些还莫得加速的部分。在计较机科学中,这叫 阿姆达尔定律 (Amdahl’s law),对组织相同成立。Anthropic 还是遇到了阿姆达尔定律的一个典型阐明:跟着组织内代码流动速率越来越快,东说念主类代码审查还是成为新的瓶颈。
而这种摩擦并不单存在于工程侧。Anthropic 职工与高才调模子配合后,新的看法、策划、器用和模拟实验出现了爆炸式增长,多到咱们根柢莫得满盈才调去逐一鼓吹。一个组织能多快发现并确立这些新瓶颈,也许会成为一种会跟着时刻持续进化的才调,并最终成为任何组织最迂回的才调。
3. AI 系统自己赢得完全递归式自我立异才调,并驱动构建它们的后继者
若是工夫才调连续沿着刻下趋势前进,而 AI 系统又赢得了那种属于“变革性东说念主类创造力”的才调,那么 AI 系统遐想并优化自身的可能性等于现实存在的。
在这个寰宇里,AI 开拓程度将完全由算力的可赢得性决定——或者说,由 AI 系统我方发现老师或推理算法着力种植的速率来决定。东说念主类在开拓中的变装将大幅松开,可能把大部分元气心灵转向对一个连接彭胀的、由 AI 系统运行的“虚构实验室”进行监督、考证与核查。咱们瞻望,一朝系统具备自动化 AI 谋划与开拓的才调,这些技巧也会升沉到其他科学领域,从而驱动改写更多学科的发展方式。
在这种将来里,对都问题究竟会被怎样料理——或者根柢料理不了——是咱们最莫得把合手的部分。模子可能满盈对都,同期也具备满盈好的谋划品尝,以至于能自行发现并杀青咱们尚未达到的新料理决策;它们以致也可能满盈“贤人”,在发现条目不足时主动罢手发展。另一种可能则是,今天模子中偶尔出现的失配问题,会跟着模子连接构建其后继者而连接积存,变得越来越常常、却越来越难以交融,直到咱们最终失去适度。也有可能,咱们根柢来不足建立、整合并考证那些匡助咱们判断我方究竟正处在哪条轨说念上的器用。
咱们对这个寰宇会长什么样莫得细腻直观,因为今天的经济仍由东说念主类和东说念主类制造的器用驱动。而从界说上说,一个由快速递归式自我立异驱动的寰宇,可能会被这种能连接自我增强的模子所主导:跟着它的才调全面超越东说念主类,并在总计这个词经济中扩散,寰宇将发生根柢变化。若是东说念主类做事不再具有竞争力,咱们很难预测那时的经济会是什么形势。
即使模子开拓真的杀青了完全自动化与递归化,咱们仍无法预测这对大大都东说念主的日常生存究竟意味着什么。阿姆达尔定律在这里相同适用。递归式智能可能会在某些领域速即杀青 《Machines of Loving Grace》 中提到的许多刚正。咱们瞻望,具身智能(也等于机器东说念主)可能会很快跟上递归式智能,并沿着近似旅途,以更低资本赢得越来越高的禀报。更苍劲的智能,也许会匡助咱们更快地建造现实寰宇中的系统,开展更高效的救命药物临床考验,发展新的和谐机制。
但只是杀青递归式立异,并不料味着工业出产方式、社会组织方式或商场运行方式会坐窝改变。更强的智能无法让咱们在几天内看见一种药物几十年后的历久反作用,无法让选举早于宪法章程的时刻举行,也无法在一个周末之内把生分东说念主变成老一又友。对大大都东说念主而言,这种将来的“体感速率”仍将由瓶颈决定——即便上游实验室还是在以算力的速率奔走。递归式智能持续越来越快地构建自身,而另一边的东说念主类寰宇仍受制于联系、治理和轨制的节拍;这两者碰撞出的将来,亦然咱们无法预测的部分。
6 咱们应该作念什么?
若是有可能有用减慢这项工夫的发展,为社会争取更多时刻去应付它所带来的巨大影响,咱们认为这概况率会是一件善事。但若是“减慢”只是让那些最不严慎的参与者在工夫上赶上来,那反而可能使总计东说念主更不安全。在缺少全球和谐机制的情况下,企业和政府都将不得不在竞争压力和地缘政事压力下,精深地作念出安全有关决策。
咱们认为,寰宇若是领有“延缓”或“暂时暂停”前沿 AI 开拓的选项,会是一件善事——这样,社会轨制建设和对都谋划才有契机跟上工夫前进的速率。Anthropic Institute 将与许多其他机构合作,开展谋划并领受活动,匡助建立一种真实的确的延缓或暂停机制所必需的系统。这些系统应当使前沿 AI 开拓者能够考证:全球其他参与者照实也还是罢手或减慢了脚步,同期也能确保坏活动者不会借由“和谐延缓”的花式暗暗加速最初。若是这样的系统存在,咱们瞻望:只须其他位于前沿或接近前沿的开拓者也在可考证前提下领受了相同活动,咱们会满足减慢以致暂时暂停。
一次有真义的延缓或暂停,要求多个资源淳朴、处在前沿或接近前沿的实验室,分处多个国度,并在相同条目下得意停驻;同期,还要求各方都能考证其他方照实停驻了。由于 AI 系统自己的独到特色,这一军控问题中的“可探伤性”(detectability——尺度低于“可考证性”)比其他工夫困难得多。老师运行比导弹辐照井更容易隐秘,它们的输入也都是通用型资源,而暗暗误期的激发又极其热烈——因为当别东说念主暂停时,谁连续鼓吹,谁就可能袭取最初地位。一个的确的暂停机制还必须明确:什么触发暂停,什么条目下铲除暂停,以及由谁来裁定。
从原则上说,这并不一定不可能。东说念主类社会也曾为其他复杂工夫建立过考证机制,比如《中导左券》(Intermediate-Range Nuclear Forces Treaty)。但那类机制用了几十年才建立起基础设施与互信。咱们还是莫得那么万古刻了。比拟之下,由单个实验室片面暂停,今天坐窝就不错作念到,但作用小得多:它只会改变谁是领跑者,却无法创造刻下真实缺失的、更平庸的社会性商议过程。
将来几个月,咱们将组织一系列商议,让计策制定者、谋划东说念主员、公民社会以过头他 AI 公司,一齐回复本文提议的一些问题,尤其是对于完全递归式自我立异,以及怎样为和谐与审议创造更好选项的问题。咱们也会把这些商议的驱散逸布出来。目前,恰是一齐谋划这些问题的窗口期,而 AI 公司除外的东说念主,也应当被纳入这场商议。
Marina Favaro 和 Jack Clark 共同撰写了本文,Santi Ruiz 提供裁剪赈济。Shan Carter、Romello Goodman 和 Nikki Makagiansar 基于 Brian Calvert 与 Jun Shern Chan 汇集的数据制作了文中视觉内容。Daniel Freeman、Jim Baker、Max Young、Sarah Pollack、Francesco Mosconi、Holden Karnofsky、Andy Jones、Kevin Troy、Anton Korinek、Meg Tong、Andrew Ho、Dan Altman、Drake Thomas、Jack Shen、Sasha de Marigny 和 Avital Balwit 提供了响应。
脚注
[^1]: METR 的关键估量目的,是 AI 系统在一组任务上达到 50% 可靠性时所对应的任务时长;不外,即便使用 80% 可靠性尺度,趋势线看起来也险些一样。
[^2]: 尤其当基准越来越偏向绽开式体式和更困难任务(例如奥数级数学问题)时,由于题目与谜底集自己可能存在歧义、题目无法求解等问题,基准往往会在低于 100% 的位置就“饱和”。
[^3]: Anthropic 料理层曾公开臆想,咱们超越 90% 的代码都是由 Claude 写的,这其中包括剧本和实验性代码。本文所说的 “>80%”,指的是合并进出产环境的代码行中,可归因于 Claude 的占比。这个目的更保守,体目前两方面:一是咱们的归因经由自己存在缺口;二是那些未被归因给 Claude 的代码行中,也包含自动生成代码和其他并非东说念主类手写的内容。
[^4]: 这轮代码产量激增,正在挤压大众共用的基础设施。看周到球大部分软件构建的平台,GitHub 在总计这个词 2025 年毛糙记载了 10 亿次代码提交;而到 2026 年年中,这一数字还是变成每周 2.75 亿次,按全年速率估算大集聚达到 140 亿次。GitHub 首席运营官默示,公司正“极其英勇地”扩容,只是为了跟上这个增长速率。
[^5]: 对于这项调查的门径学细节,可参见 Claude Opus 4.7 System Card 的第 2.3.5 节。
[^6]: 许多受访者可能并未仔细斟酌应怎样校正这个问题中的多样偏差或界说细节,而 METR 最近的谋划泄漏,开拓者对 AI 带来出产率种植的主不雅臆想,往往会高于推行值。
[^7]: 具体加速能达到多大程度,很大程度上取决于肇始代码自己还留有若干优化空间,因此这里的都备倍数不应被径直解读为现实寰宇中的老师加速效果。更有信息量的是这种“同条目对比”所提供的比较:不同模子之间(当年一年从约 3 倍到约 52 倍)以及模子与老到东说念主类之间(在相同任务上,东说念主类 4 到 8 小时作念到约 4 倍)的各别。
博亚体育app中国官网入口[^8]: 为了查验裁判偏置NBA下注(中国)官网,咱们还在另一组 127 个时刻上作念了相同测试;这些时刻里,东说念主类那时的下一步本来就还是很强(与原始测试集“东说念主类目的存在立异空间”不同)。在这组对照中,模子给出的建议惟有毛糙 20% 的情况下被判定为更优。